
The current narrative surrounding generative AI is obsessed with one ultimate destination: full automation. We are constantly promised a future where you can feed a text prompt into an LLM and watch it autonomously build entire applications, design flawless interfaces, or write comprehensive project plans.
But anyone who has spent time leading engineering teams, communicating with business partners and other stakeholders, knows a fundamental truth: specifications are never exact. Because of this inherent gap, aiming for full automation is not just incredibly difficult—it is superfluous. Instead, we need to shift our focus toward a more pragmatic paradigm: Cooperative, Interactive AI.
The Fallacy of the “Perfect Prompt”
In software development and product design, the gap between what a client says they want, what the project manager writes down, and what actually needs to be built is massive.
Translating these vague, evolving human desires into functional systems requires experience, contextual judgment, and real-time negotiation—not statistical averaging of training data or LLM “intuition.”
This introduces a paradox – the Specification Bottleneck (a mathematically modeled reality, see Rozier, 2016 or more specifically, Liang, 2026):
The Specification Bottleneck: > To get a fully automated LLM to output a flawless, production-ready implementation, your input specification must be so detailed, edge-case-proof, and unambiguous that creating the prompt itself requires as much expert effort as writing the actual code.
If an expert has to spend hours crafting a hyper-specific, multi-page prompt to get a correct automated output, we haven’t actually saved any labor. We have just traded coding for a highly tedious form of “prompt programming.”
The Cooperative Paradigm: Domain-Expert Agents
Instead of trying to bypass the human, we should design AI systems that actively collaborate with us. I propose a cooperative ecosystem where specialized, domain-expert agents act as active sounding boards for designers, project managers, and implementers.
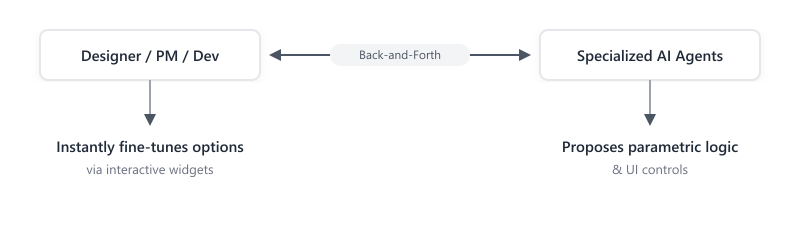
In this workflow:
- The Human provides high-level intent, guardrails, and subjective taste.
- The AI does the heavy lifting of generating initial structures, calculating math, or retrieving boilerplate logic.
- The Interface allows both parties to refine the output dynamically.
This brings us to the core technical and UX principle of this approach: interactivity over re-prompting.
The “Interactive Slider” Principle
To make Cooperative AI work, we must abandon the “chat box as the sole interface” mentality. When we ask an AI to make a change, the output shouldn’t just be a static guess. It should be a parametric proposal paired with interactive controls.
Consider a simple design task: adjusting the saturation of an interface element.
The Old, Fragmented Way (Re-prompting)
- User: “Make the main button color less saturated.”
- LLM: [Guesses and outputs a hex code at 25% saturation]
- User: “That’s a bit too gray. Make it slightly more saturated.”
- LLM: [Processes again, outputs hex code at 35%]
- User: “Still not quite right…”
This cycle is incredibly frustrating, slow, and expensive.
The Cooperative Way (Interactive Widgets)
- User: “Make the main button color less saturated.”
- LLM: Proposes a mathematical function to calculate the saturation, binds it to the element, and renders an interactive slider widget directly in the chat interface.
- User: Drags the slider in real-time, instantly seeing the changes at 60 frames per second, and stops at the exact sweet spot (e.g., 32%).
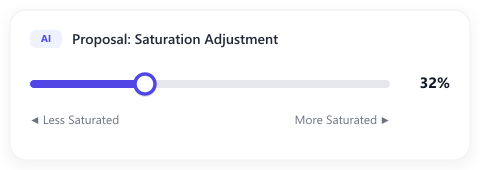
By connecting the LLM’s conceptual understanding to functional, client-side code, we allow the human to handle the fine-tuning without ever having to send another prompt.
The Economic and Practical Reality of 2026
Designing AI this way isn’t just a win for user experience; it is a financial and technical necessity in today’s landscape.
- The Death of Subsidized Inference: The era of dirt-cheap, subsidized venture capital AI credits is behind us. API calls are expensive, and running large models for micro-adjustments scales costs rapidly.
- The Latency Constraint: Even the fastest LLMs take hundreds of milliseconds to generate a token and return a response. Dragging a local UI slider takes less than 16 milliseconds.
- Token Conservation: By generating the control mechanism (the slider and the function) instead of repeatedly generating new content, we optimize token consumption. We pay the inference cost once, and handle the rest of the iteration locally.
Empower, Don’t Replace
Full automation is a pipe dream born from a misunderstanding of how creative and technical work actually happens. Specifications are living, breathing entities. They are refined through iteration, experimentation, and human eye-balling.
As builders and researchers, our goal shouldn’t be to write the human out of the equation. Our goal should be to build interfaces that turn LLMs into the ultimate leverage—giving us highly specialized tools, instant prototypes, and interactive widgets that let us sculpt our ideas in real-time.
The future isn’t autonomous. The future is cooperative.
This post was written with the help of Generative AI.
Image of my cat as symbolic reference 😉


